导语
TensorFlow 是一款谷歌的深度学习开源框架,有着比较详细的官方文档说明,社区也比较活跃。底层的是通过C/C++来实现,同时提供了python, C++, Java的接口。在这里我们采用的是python的接口,在《机器学习实战》一书中,作者所机器学习之所以经常采用python来作为编程语言,是因为相比于C++来说,python语法更加简单,可读,是“可执行的伪代码”,可以让我们快速验证算法的准确性,需要进一步优化再采用性能更高的语言如C/C++。当然了,这里tensorflow已经帮我们包装好了接口,那何乐而不为呢。
安装
TensorFlow的安装总的来说还是比较简单的,如果有pip这个python的包管理工具,通过
1 | pip install -upgrade tensorflow |
就可以完成安装了,这里采用的是python 2.7, pip对应的也是python 2.7的版本。
我是在mac OSX 下进行安装的,安装过程中遇到了两个小问题:
- tensorflow依赖six这个库,而mac自带了six,所以在安装过程中可能会引发一些冲突导致安装失败。
- 还有因为之前我安装了多个版本的python,有通过homebrew安装的python2.7以及pip,还有mac自带的python2.7和pip,如果命令行pip和python的指令对应到的不是相应的python2.7和pip,在运行过程中就会找不到通过pip安装的一些库,进而导致问题出现。
所以建议保留一个版本的python就好了。具体遇到问题的时候google一下,应该都是可以解决的。后来我又在阿里云的服务器上,系统是Ubuntu 16.04LTS,这次安装就很顺利,由于没有多个python,直接通过pip安装就很快地安装成功了。
具体可以参考官方的教程Installing TensorFlow on Ubuntu,这里所安装的都是CPU版本。如果需要安装GPU版本可以再参考官方的指南,比较详细。
入门——手写体识别
下面,就通过运行和详读官方所给出的demo教程,mnist_softmax这个手写体识别教程来了解tensorflow这个框架。
框架
一般机器学习的主要过程都是下面这个样子的:

minist_softmax 的框架也大致如此,下面就具体地来分析一下每一个步骤。
准备数据
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:
每一张图片包含着一个手写的数字,和一个标签代表这个手写字体所代表的数字是多少。
通过下列的代码可以读取文件中的mnist数据集。
1 | #import data |
2 | from tensorflow.examples.tutorials.mnist import input_data |
3 | mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) |
每一张图片是一个28*28 像素的图片,可以通过一个矩阵来表示这个图片,非零代表有颜色的地方,0代表空白的地方。
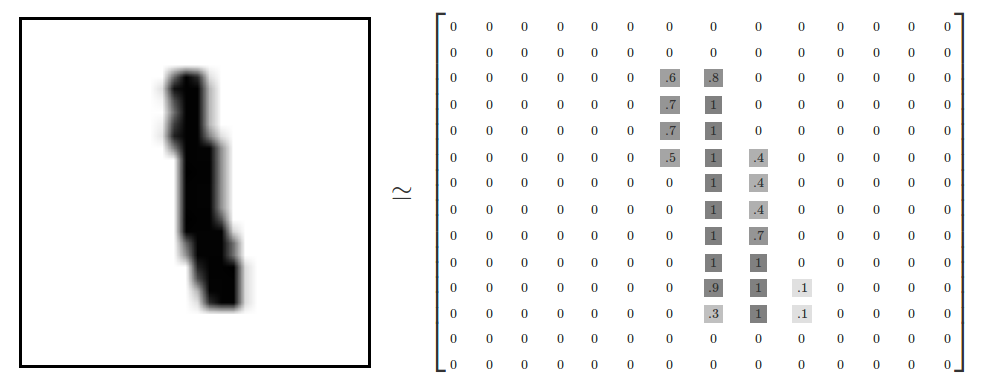
设置模型
1 | # Create the model |
2 | x = tf.placeholder(tf.float32, [None, 784]) |
3 | W = tf.Variable(tf.zeros([784, 10])) |
4 | b = tf.Variable(tf.zeros([10])) |
5 | y = tf.matmul(x, W) + b |
x是通过placeholder创建的一个占位符,数据的类型是float32类型,None代表可以输入任意张mnist图片,每张图片展开成28x28=784维的向量。模型同时也需要权值和偏值,这里采用Variable,它代表了一个可以修改的张量。
y=tf.matmul(x, W) + b就代表了$$y = Wx+b$$ ,可以发现y也会是一个10维的向量,110维度,分别代表了这个数字是09的概率大小,概率最大者就代表这个手写体被预测为什么。
设置cost function
在机器学习中,需要定义一个函数,来检测模型的好坏。这个函数称之为cost function,在训练的目的就是最小化这个函数。这里采用了交叉熵(cross-entropy) 来作为cost function。
首先创建一个新的占位符,用来输入正确的值。
1 | y_ = tf.placeholder(tf.float32, [None, 10]) |
softmax交叉熵
然后通过tf.nn.softmax_cross_entropy_with_logits来计算交叉熵:
1 | cross_entropy = tf.reduce_mean( |
2 | tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)) |
其中:
- labels: Each row
labels[i]must be a valid probability distribution. - logits: Unscaled log probabilities.
梯度下降法
通过梯度下降法来,以0.5的学习速率来寻找交叉熵的局部最小值。
1 | train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) |
初始化变量,创建session
1 | sess = tf.InteractiveSession() |
2 | tf.global_variables_initializer().run() |
通过sess = tf.InteractiveSession()创建了一个交互式的session,如在shell中。然后通过tf.global_variables_initializer().run()来初始化之前所声明的变量。
那什么是session呢?
有几点关于tensorflow,是我们所需要知道的。
- 使用图 (graph) 来表示计算任务.
- 在被称之为
会话 (Session)的上下文 (context) 中执行图. - 使用 tensor 表示数据.
- 通过
变量 (Variable)维护状态. - 使用 feed 和 fetch 可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据.
所以,我们的计算都是要在session这样子一个上下文环境中来进行的。
训练
开始训练模型,让模型循环训练1000次,每一次随机抽取100个数据来进行训练,然后回到train_step通过梯度下降的方法来进行训练。这称之为随机训练(stochastic training)。
1 | # Train |
2 | for _ in range(1000): |
3 | batch_xs, batch_ys = mnist.train.next_batch(100) |
4 | sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) |
这样子每次训练可以使用不同的数据集,降低计算开销,又学习到数据集合的总体数据特征。
测试
1 | # Test trained model |
2 | correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) |
3 | accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) |
4 | print(sess.run(accuracy, feed_dict={x: mnist.test.images, |
5 | y_: mnist.test.labels |
通过argmax(y, 1)可以找到y中最大值的下标,然后通过比较y_和y的下标是否相同,如果相同就是正确的为1否则为0,然后把布尔值当成浮点数,进行取平均值,得到一个预测的准确率。
封装
上述的过程被封装为了一个main() 模块
如果通过命令行执行就满足__name__ == '__main__'这个条件,程序开始执行。允许在命令行中指定另外的数据路径。
1 | if __name__ == '__main__': |
2 | parser = argparse.ArgumentParser() |
3 | parser.add_argument('--data_dir', type=str, default='/tmp/tensorflow/mnist/input_data', |
4 | help='Directory for storing input data') |
5 | FLAGS, unparsed = parser.parse_known_args() |
6 | tf.app.run(main=main, argv=[sys.argv[0]] + unparsed) |
Softmax
可以发现,在上述代码过程中,都是直接很方便的使用了tensorflow所封装完的方法。并没有具体的了解到softmax是如何实现的,下面简单介绍一些原理。通过softmax函数能够计算个图片为数i的概率大小。它能将任意k维的数据压缩到另外k维。
$$ evidence_i = \sum_j W_{i,j}x_j+b_i$$
用官方的一张图片来解释就是这样子:

具体的数学原理就不再阐述了。
运行结果

得到了运行mnist_softmax方法进行训练的准确率。
总结
了解完这个demo代码也可以发现tensorflow的一个特色,它并不单独地运行单一的函数计算,而是先用途描述一系列可交互的计算操作流程,然后一次性提交到外部运行,通过外部底层语言可以实现高效的运算功能,然后又可以减少外部计算切换回python的开销。这是之前我所用过的matlab和c++来写机器学习相关算法所不同的地方,只有在流程中的训练和测试阶段才真正把数据交给底层库进行实际运算,而且每次训练一般是批量执行一批数据的。
参考
- TensorFlow 官方教程: MNIST For ML Beginners
- 腾讯Bugly: 人人都可以做深度学习应用:入门
- TensorFlow基本使用
